Bernd J. Kröger: research
Neural model of speech processing (production, perception, acquisition)
See also:
Wikipedia: Neurocomputational Speech Processing
Our model is developed under the paradigms of theoretical neuroscience or systemic neuroscience
1 ) A time-explicit spiking neuron model for speech production and speech perception using the NENGO neural
modeling framework (see: www.nengo.ca)

|
The architecture of the neural model of speech processing (see references up to 2023) including location of buffers of the cognitive and sensorimotor processing part within the brain |
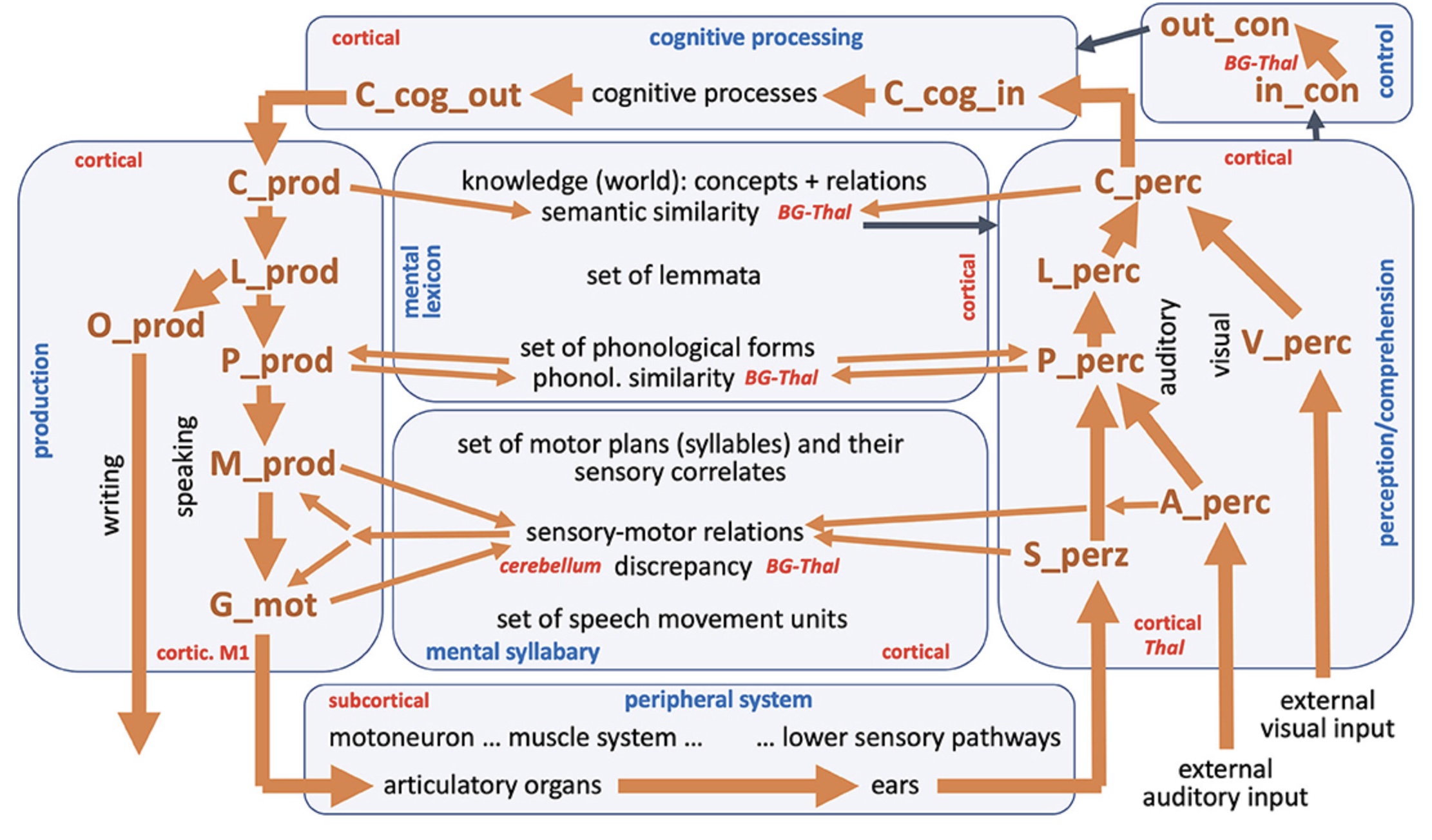
|
The architecture of the neural model of speech processing developed using the NENGO.ai-approach (see references up to 2020) |
- Presentation (slides): Overview: Current status of our neural model of speech processing. see: 2021pdf)
- Presentation (videos; YouTube Playlist): Current status of our neural model of speech processing. see: YouTube)
- Papers on this topic started in 2014 (see publications and references below)
- Presentation: ASS
- NENGO model: (see sources)
References:
- Kröger BJ (2023) Modeling speech processing in case of neurogenic speech and language disorders: neural dysfunctions, brain lesions, and speech behavior. Frontiers in Language Sciences 2. DOI: 10.3389/flang.2023.1100774 (full paper)
- Kröger BJ (2023) The NEF-SPA Approach as a Framework for Developing a Neurobiologically Inspired Spiking Neural Network Model for Speech Production. Journal of Integrative Neuroscience 22: 124. DOI: 10.31083/j.jin2205124 (full paper)
full paper) - Kröger BJ (2022) Computer-Implemented Articulatory Models for Speech Production: A Review. Frontiers in Robotics and AI 9: 796739, doi: 10.3389/frobt.2022.79673 (full paper)
- Kroeger BJ, Stille C, Blouw P, Bekolay T, Stewart TC (2020) Hierarchical sequencing and feedforward and feedback control mechanisms in speech production: A preliminary approach for modeling normal and disordered speech. Frontiers in Computational Neuroscience, 14, 99, doi=10.3389/fncom.2020.573554 (full paper)
- Kroeger, BJ, Bekolay T, Blouw P, Stewart TC (2020) Developing a model of speech production using the Neural Engineering Framework (NEF) and the Semantic Pointer Architecture (SPA). Proceedings of the International Seminar on Speech Production ISSP2020. Yale University, New Haven, CT. (full_paper), (poster), (video_intro_1min), (video_poster_5min), (video_syllable_init), (video_gesture_init)
- Stille C, Bekolay T, Blouw P, Kröger BJ (2020) Modeling the Mental Lexicon as Part of Long-Term and Working Memory and Simulating Lexical Access in a Naming Task Including Semantic and Phonological Cues. Frontiers in Psychology, (full paper)
- Stille C, Bekolay T, Blouw P, Kröger BJ (2019) Natural language processing in large-scale neural models for medical screenings. Frontiers in Robotics and AI (Computational Intelligence) doi: 10.3389/frobt.2019.00062 (doi)
- Kröger BJ, Bekolay T (2019) Neural Modeling of Speech Processing and Speech Learning. An Introduction. Springer International Publishing. (SpringerShop) ISBN 978-3-030-15852-1
- Kröger BJ (2018) Neuronale Modellierung der Sprachverarbeitung und des Sprachlernens. Eine Einführung. Springer Verlag, Germany. (SpringerShop) ISBN 978-3-662-55459-3, (SpringerOnline, SpringerLink)
- Senft V, Stewart TC, Bekolay T, Eliasmith C, Kröger BJ (2018) Inhibiting Basal Ganglia Regions Reduces Syllable Sequencing Errors in Parkinson's Disease: A Computer Simulation Study. Frontiers in Computational Neuroscience 12:41 (doi)
- Kröger BJ (2018) Neuronale Modellierung der Sprachverarbeitung und des Sprachlernens. Eine Einführung. Springer Verlag, Germany. (SpringerShop) ISBN 978-3-662-55459-3, (SpringerOnline, SpringerLink)
- Kröger BJ, Crawford E, Bekolay T, Eliasmith C (2016) Modeling interactions between speech production and perception: speech error detection at semantic and phonological levels and the inner speech loop. Frontiers in Computational Neuroscience 10:51 (doi)
- Senft V, Stewart TC, Bekolay T, Eliasmith C, Kröger BJ (2016) Reduction of dopamine in basal ganglia and its effects on syllable sequencing in speech: A computer simulation study. Basal Ganglia 6: 7-17 (doi, pdf)
- Kröger BJ, Bekolay T, Blouw P (2016) Modeling motor planning in speech processing using the Neural Engineering Framework. In: Jokisch O (Ed.) Studientexte zur Sprachkommunikation: Elektronische Sprachsignalverarbeitung 2016 (TUDpress, Dresden, Germany), pp. 15-22 (ISBN: 978-3-95908-040-8) (pdf)
- Kröger BJ, Bekolay T, Eliasmith C (2014) Modeling speech production using the Neural Engineering Framework. Proceedings of CogInfoCom 2014 (Vetri sul Mare, Italy) pp. 203-208 (ISBN: 978-1-4799-7279-1) and IEEE Xplore Digital Library DOI=10.1109/CogInfoCom.2014.7020446 (doi, pdf)
2 ) A conventional connectionist SOM and GSOM neural model for production, perception and acqusition of speech is developed on the basis of two different articulatory-acoustic models

|
The architecture of the model of speech processing using classsical connectionist approaches (see publications below) |
- see pdfs of an introductory lecture: part 1: production and acquisition,
part 2: perception and action,
part 3: further ideas,
part 4: semantics
- Papers on this topic started in 2006 (see publications and references below)
- Two different articulatory-acoustic models were used:
First trials with geometrical approach (Birkholz model)
Later trials with physiological approach (Dang-Honda model)
- GSOM model: (see sources)
References:
- Kröger BJ, Bafna T, Cao M (2019) Emergence of an action repository as part of a biologically inspired model of speech processing:
the role of somatosensory information in learning phonetic-phonological sound features. Frontiers in Psychology, doi: 10.3389/fpsyg.2019.01462
(doi)
- Kröger BJ (2018) Neuronale Modellierung der Sprachverarbeitung und des Sprachlernens. Eine Einführung. Springer Verlag, Germany.
(SpringerShop) ISBN 978-3-662-55459-3,
(SpringerOnline, SpringerLink)
- Kröger BJ, Cao M (2015) The emergence of phonetic-phonological features in a biologically inspired model of speech processing. Journal of Phonetics 53:88-100 (doi, pdf)
- Kröger BJ, Kannampuzha J, Kaufmann E (2014) Associative learning and self-organization as basic principles for simulating
speech acquisition, speech production, and speech perception. EPJ Nonlinear Biomedical Physics 2:2
(doi,
pdf)
(Fig8_large,
Fig9_large,
Fig10_large)
- Kröger BJ, Heim S (2013) How could a self-organizing associative speech action repository (SAR) be represented in the brain?
Hallesche Schriften zur Sprechwissenschaft und Phonetik 45: 61-68 (doi,
pdf)
- Kröger BJ, Kannampuzha J, Eckers C, Heim S, Kaufmann E, Neuschaefer-Rube C (2012) The neurophonetic model of speech processing ACT:
structure, knowledge acquisition, and function modes. In: Esposito A, Esposito AM, Vinciarelli A, Hoffmann R, Müller VC (eds.)
Cognitive Behavioural Systems, LNCS 7403 (Springer, Heidelberg, Berlin), pp. 398-404
(pdf)
- Kröger BJ, Birkholz P, Kannampuzha J, Kaufmann E, Neuschaefer-Rube C (2011)
Towards the acquisition of a sensorimotor vocal tract action repository within a neural model of speech processing.
In: Esposito A, Vinciarelli A, Vicsi K, Pelachaud C, Nijholt A (eds.) Analysis of Verbal and Nonverbal Communication
and Enactment: The Processing Issues. LNCS 6800 (Springer, Berlin), pp. 287-293
(pdf)
- Kröger BJ, Birkholz P, Neuschaefer-Rube C (2011) Towards an articulation-based developmental robotics approach for
word processing in face-to-face communication. PALADYN Journal of Behavioral Robotics 2: 82-93
(pdf,
doi)
- Kröger BJ, Miller N, Lowit A, Neuschaefer-Rube C. (2011) Defective neural motor speech mappings as a source for apraxia of speech:
Evidence from a quantitative neural model of speech processing. In: Lowit A, Kent R (eds.)
Assessment of Motor Speech Disorders. (Plural Publishing, San Diego, CA) pp. 325-346
(pdf)
- Kröger BJ, Kannampuzha J, Neuschaefer-Rube C (2009) Towards a neurocomputational model of speech
production and perception. Speech Communication 51: 793-809
(pdf,
doi)
Neural model for sentence processing
simple approach: parsing and producing of SPO-sentences using a linear parser, programmed using
NENGO
here: the ipynb source code for parsing: ipynb
here: the ipynb source code for production: ipynb
next goal: programming a nonlinear parser, capable of processing complex sentences
Simulation of production mechanisms of voice, reeds and brass

|
Simulation models for (a) reeds, (b) brass, and (c) voice (see publications below) |
References:
- Kröger BJ (2019) On the production mechanisms of the singer’s formant. Proceedings of the 23rd International Congress on Acoustics (Aachen, Germany, ISBN 978-3-939296-15-7), pp. 4568-4575 (pdf)
- Kröger BJ (2019) Differences and similarities in the production mechanism of reeds, brass, and voice: the source-filter viewpoint. Proceedings of the 23rd International Congress on Acoustics (Aachen, Germany, ISBN 978-3-939296-15-7), pp. 6494-6501 (pdf)
Classification of voice quality
Production-Perception Approach (PPA): Stimuli are generated using a self-oszillating two-mass model
(see: VocalTractLab)

|
Try to imitate the auditory stimuli, following the articulatory explanations (not for rough and instable voice)
|
Classification of Voice Quality using GIRBAS Scale
(following: PH Dejonckere et al. 1996, Revue de Laryngolgie - Otologie - Rhinologie 117, 219-224)
(description of voice features: see also ASHA CAPE-V 2002:
pdf)
four-point scale of severity: 0="normal/no", 1="slight", 2="moderate", 3="severe" need to be set for the following six features:
- Overall Grade of Hoarseness (G): global, integrated impression of voice deviance (here: mean value of the next five voice features)
- Instability (I): Fluctuation of voice quality over time and/or unstable vocal fold oscillations
- Roughness (R): vocal fold oscillations with perceivable irregularities
- Breathiness (B): stable vocal fold oscillations but with audible air escape / with audible additional noise
- Asthenia (A): stable vocal fold oscillations but too weak vocal effort (i.e. hypofunction)
- Strained Quality (S): stable vocal fold oscillations but excessive (i.e. too strong) vocal effort (i.e. hyperfunction)
References:
- Kröger BJ (2018) Neurocomputational models of voice and speech perception, In: S Frühholz & P Belin (eds.) The Oxford Handbook of Voice Perception, Oxford University Press (ISBN: 9780198743187), pp. 743-756 (chapter 34) (link)
- Kroeger BJ, Weise M (in preparation)
Speech acquisition: mental syllabary
Generation of mono-syllables (and bisyllabic words) of Standard German using an action-based articulatory production model
(using: VocalTractLab) and speaker
JD3.speaker
The rows of the table are ordered with respect to type of syllable (V, CV, CCV, ...) and type of vowels, consonant and consonant clusters (01, 02. 03, ...)
The colums 1 and 2 of the table reflect type of syllable; column 3: a typical gesture score; column 4: examples
| [V] | 01: V = long vowel, diphtong (incl. vowel plus vocalic /r/), triphthong(= diphthong plus vocalic /r/): well-timed speech actions: vocalic, glottal abduction, lung pressure action; two actions for intonation were added; the utterence ends with last lung pressure action |
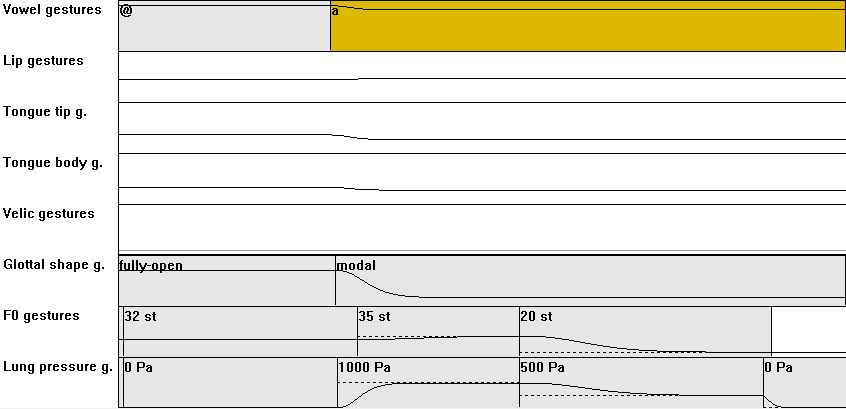
|
long:
i:
e:
E:
a:
o:
u:
y:
2:
@: diphthong: aI aU OI long+voc/r/: i:6 e:6 E:6 a:6 o:6 u:6 y:6 2:6 triphthong: aI6 aU6 OI6 articulation: V01_ges.zip |
| [V] | 02: from V = long to V = short vowel and reduced vowel: compared to V01: shorten vowel; end of utterance is determined by last lung pressure action (0Pa); function of this action is like consonantal closure in syllable offset! short and reduced vowel only occurr in CV context (see below; figure shows [d@]) |
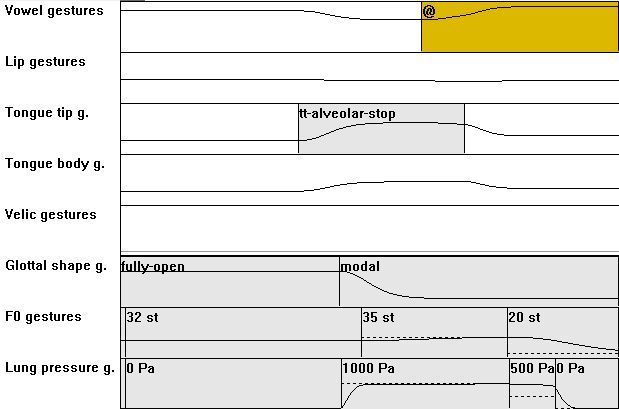
|
audios for variation of V in /CV/: see above and below; V = long, short, reduced |
| [CV] | 01: from V to VC with C = voiced plosive, lateral, or /r/ as fricative realization: compared to V01/V02: in addition: consonantal obstruction action |

|
long:
ba:
da:
ga:
la:
ra:
bu:
du:
gu:
lu:
ru:
bi:
di:
gi:
li:
ri: diphthong: baI baU daU daI gaU gaI gOI laU raU rOI raI long+voc/r/: bi:6 bE:6 di:6 dE:6 gi:6 le:6 ru:6 triphthong: baU6 baI6 raI6 short: ba da ga la ra reduced: b@ d@ g@ l@ r@ words: ga:b@ ga:d@ la:g@ ba:r@ gal@ gar@ articulation: CV01_ges.zip |
| [CV] | 02: from C = lateral to C = nasal: compared to VC01: add a velopharyngeal opening action |
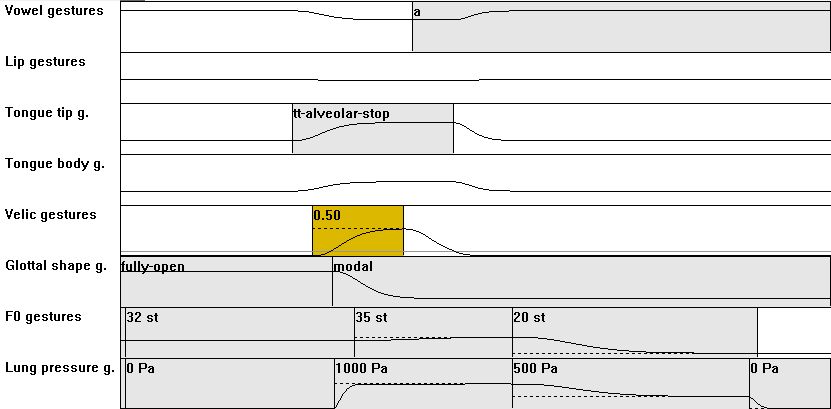
|
long:
ma:
na:
mi:
ni:
mu:
nu: diphthong: maU naU maI naI mOI nOI long+voc/r/: mi:6 me:6 mE:6 mo:6 nE:6 na:6 nu:6 triphthong: maU6 maI6 short: ma na reduced: m@ n@ words: da:m@ pan@ articulation: CV02_ges.zip |
| [CV] | 03: from C = voiced to C = voiceless plosive: compared to CV01: shift of consonantal obstruction action to the left in order to allow VOT; add a gottal abduction action (logner duration of initial glottal opening action) |
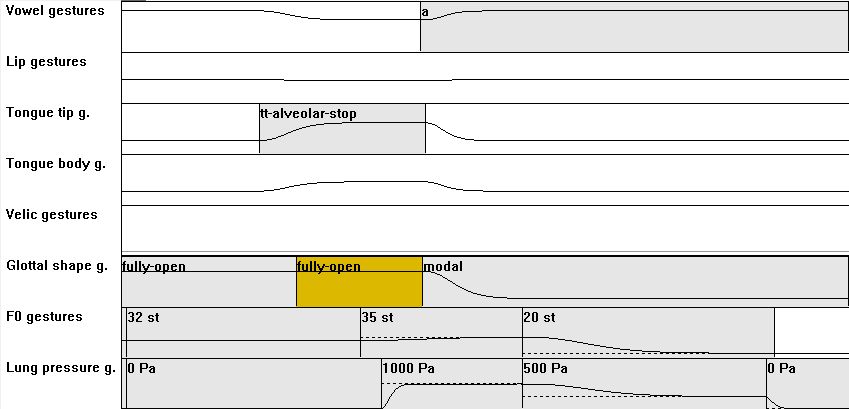
|
long:
pa:
ta:
ka:
pi:
ti:
ki:
pu:
tu:
ku: diphthong: paI paU pOI taI taU tOI kaI kaU kOI long+voc/r/: pi:6 pu:6 ti:6 ty:6 te:6 to:6 tu:6 ke:6 ko:6 ku:6 triphthong: paU6 taU6 tOI6 short: pa ta ka reduced: p@ t@ k@ words: kap@ pa:t@ bak@ articulation: CV03_ges.zip |
| [CV] | 04: from C = voiceless plosive to C = voiceless fricative: compared to CV03: longer duration of glottal opening action over whole consonatal obstruction; slightly right shift of consonantal obstruction action (more temporal overlap with vocalic action) |
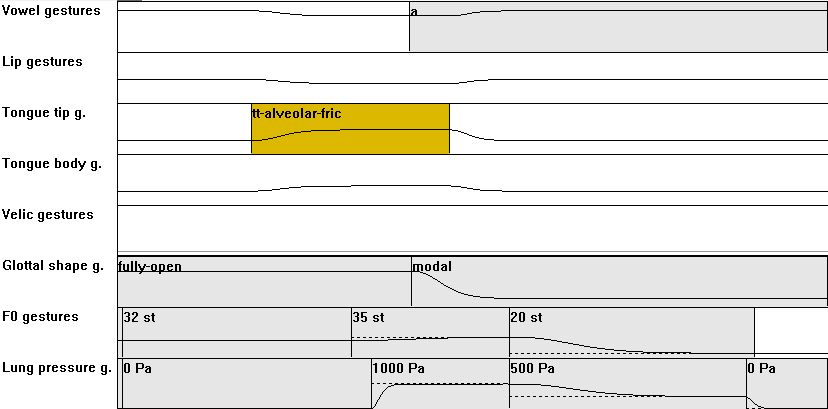
|
long:
fa:
sa:
Sa:
ci:
xa: diphthong: faU faI SaU SaI SOI long+voc/r/: fi:r fy:r fE:r fo:r fu:r Si:r Sy:r SE:r Sa:r So:r Su:r triphtong: faIr fOIr SaUr short: fa sa Sa ca xa reduced: f@ s@ S@ c@ x@ words: ?af@ kas@ laS@ kYc@ la:x@ articulation: CV04_ges.zip |
| [CV] | 05: from C = voiceless to C = voiced fricative: compared to CV04: add a glottal adduction action (here called "breathy"), leading to phonation and a leak in order to generate enough air flow for frication noise during production of voiced fricative |
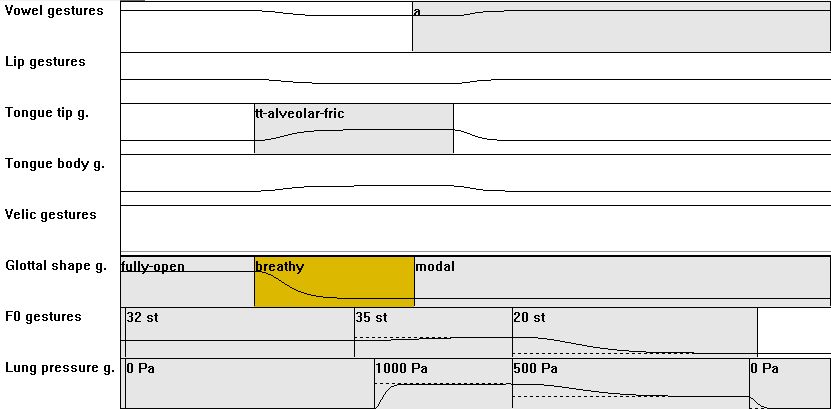
|
long:
va:
za:
Za:
ja: diphthong: vaU vaI zaU zaI jaU triphtong: vaIr zaUr short: va za Za ja reduced: v@ z@ Z@ j@ words: m2:v@ va:z@ ga:z@ ko:j@ articulation: CV05_ges.zip |
| [CV] | 06: from V CV with C = glottal stop /?/: compared to V01/V02: add a glottal stop action (strong adduction); slightly later onset of lung pressure action (1000Pa) |
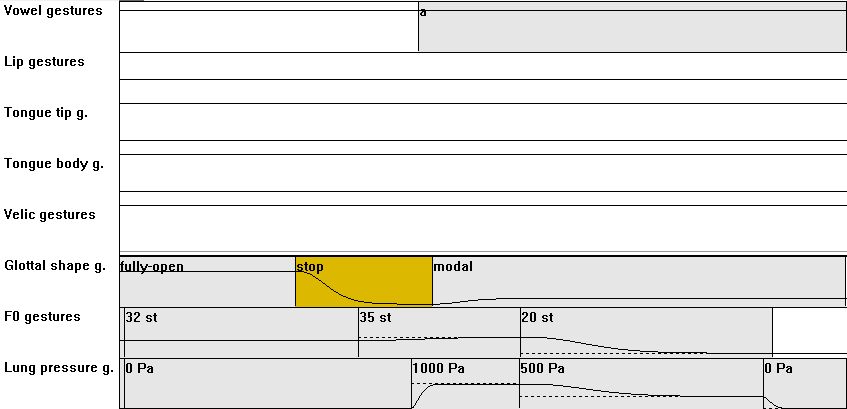
|
long:
?i:
?a:
?u:
?y: diphthong: ?aI ?OI ?aU triphthong: short/reduced: ?I ?a ?U ?Y ?@ articulation: CV06_ges.zip |
| [CV] | 07: from /?V/ to /hV/ with /h/ = glottal voiceless fricative: compared to CV04 (oral voiceless fricative): delete the oral consonantal obstruction action; just: long glottal abduction action (voiceless) plus synchronous lung pressure action (1000Pa) |
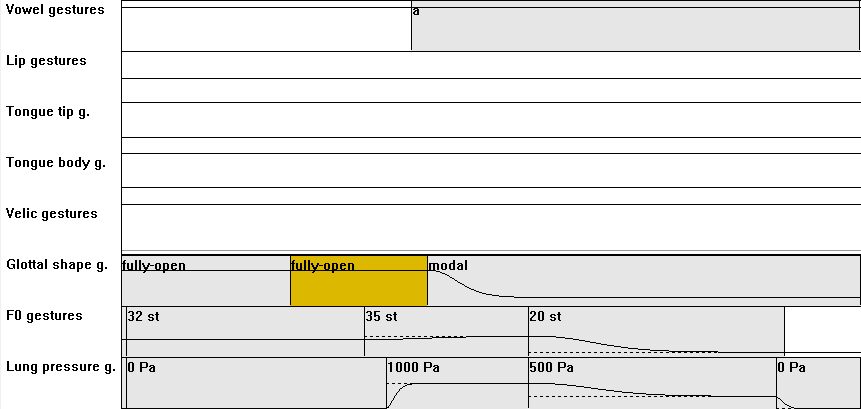
|
V=long:
hi:
ha:
hu:
hy: diphthong: haI hOI haU triphtong: V=short/reduced: hI ha hU hY h@ words: ?e:(h)@ my:(h)@ articulation: CV07_ges.zip |
| [CCV] | 01: from CV (CV01-CV03) to CCV01 with C1 = plosives and C2 = lateral, nasal, or /r/ as fricative realization: mainly add one consonantal obstruction action; other changes of velic, glottal, F0 and lung actions similar as in CV01-CV03 |

|
V=[a:]:
bla:
bra:
gla:
gna:
gra:
pla:
pra:
kla:
kna:
kra: V=[i:]: bli: bri: gli: gni: gri: pli: pri: kli: kni: kri: V=[u:]: blu: bru: glu: gnu: gru: plu: klu: knu: kru: articulation: CCV01_ges.zip |
| [CCV] | 02: from CCV01 to CCV02 with C1 = voiceless fricative or C1C2 are both voiceless: changes of actions similar to CV01-CV05 |
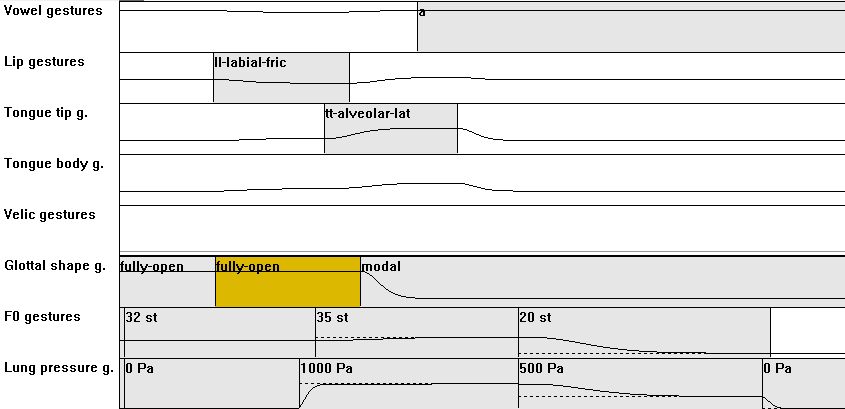
|
V=[a:]:
fla:
Sla:
Sna:
pfa:
Spa:
Sta: V=[i:]: fli: Sli: Sni: pfi: Spi: Sti: V=[u:]: flu: Slu: Snu: pfu: Spu: Stu: articulation: CCV02_ges.zip |
| [CVC] | 01: from CV01...CV09 to CVC01 with C(final) = nasal or lateral: overlap of consonantal closure action with last part of preceding vowel and co-occurring velopharyngeal opening action in case of nasal |
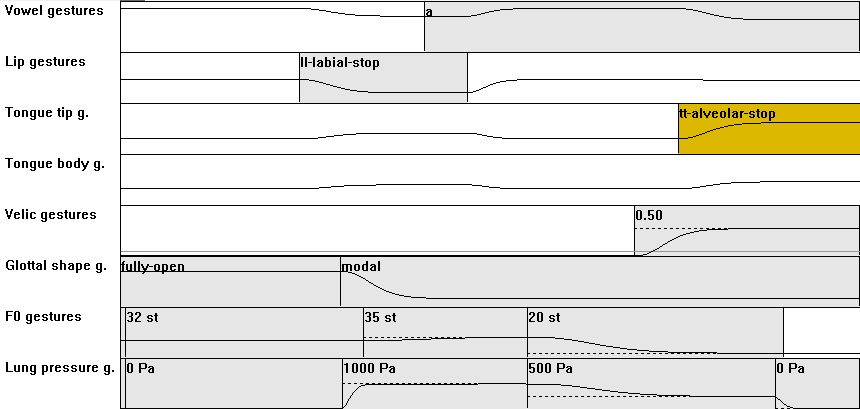
|
from CV01:
ba:n
da:m
ga:n
la:m
ga:b@n
ga:r@n
gal@n
ban
bal
dam
dIl
gan
lam
ran
da:m@n
pan@n
m2:b@l from CV02: mo:n ma:l man mOl na:m nIm from CV03: pa:n pa:l kan kal ka:m tIm tEl from CV04: faIn fal Sal SaUm ?af@n vaf@l lax@n vax@n vaf@n la:x@n ?a:x@n from CV05: va:m va:n va:l van val vIl vOl jan m2:v@n va:z@n ko:j@n from CV07: ?i:m ?Im ?i:n ?In ?a:m ?a:l ?am ?a:n ?an ?al from CV08: ha:n hu:n ho:l ham hIm han hal hIn ?e:(h)@n my:(h)@n articulation: CVC01_ges.zip |
| [CVC] | 02: from CV01...CV09 to CVC02 with C(final) = voiceless plosive: overlap of consonantal closure action with last part of preceding vowel and co-occurring glottal opening action |
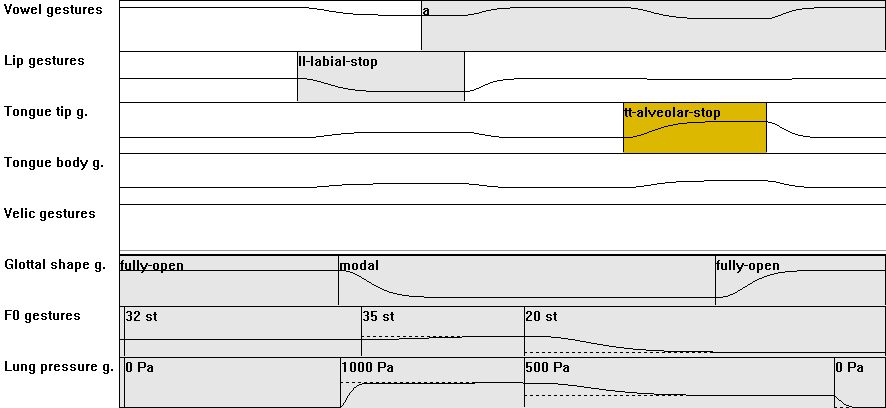
|
from CV01:
ba:t
ba:k
bak
bu:k
bu:p
lo:t
lo:p
ra:t
rUk from CV02: ma:t mat na:t nEp from CV03: pak kap pat from CV04: fIt SIk SOk from CV05: za:t zak zat vat jUp jUk from CV07: ?a:t ?Et ?Ek ?ap from CV08: ha:t hu:t hat hIk hak articulation: CVC02_ges.zip |
| [CVC] | 03: from CV01...CV09 to CVC02 with C(final) = voiceless fricative: overlap of consonantal obstruction action with last part of preceding vowel and co-occurring glottal opening action |

|
from CV01:
ga:s
la:s
laUs
laIc
das
bas
dax
dOx
lax
rax
laS
raS
ri:f
raIf
rIf
dIc
daIc
rIc
raIc
lIc from CV02: ma:s nas naS na:x mi:f mUf mUs mIc from CV03: pas paS kES kEs tax tIS tu:x taIc ki:s from CV04: fu:s fi:s fas fIS fES fUS Sax SaIc Si:f SIf from CV05: vaIc vas vaS vax vIS vu:S zax zIc from CV07: ?a:s ?aUf ?aIs ?aUs ?as ?ax ?aS ?uf ?Ox from CV08: has haf huX haS haIs haUs hOIs hi:s articulation: CVC03_ges.zip |
Articulatory-acoustic synthesis of speech and singing
1 ) A fast 2D-articulatory-acoustic speech synthesizer using the vocal tract action control concept (Kröger et al. 2010,
Cognitive Processing 11: 187-205, pdf) and based on our
earlier geometrical model (Kröger et al. 2005, ZASPiL 40: 79-94, pdf)
has been reprogrammed in Python. Currently we work on integration of this fast speech synthesizer into a
neuroscience-based model of speech learning.
An older version of the synthesizer was based on a simple Köln articulatory model, but used the same acoustic model. (see:
Kröger et al. 1993 Journal Phonetica, Kröger 1998 Habil.-Thesis)
Video examples:
- Generation of area function from Köln articulatory model for sentence "Das ist mein Haus": am.avi
- Generation of acoustic speech signal from area function for sentence "Das ist mein Haus": ar.avi
- Visualization of air flow and pressure within vocal tract for vowel /a/: one glottal period: as.avi
- Visualization glottal area, glottal flow, its time derivative, and mouth radiated sound pressure for sentence "Das ist mein Haus": re.avi
Audio examples:
- Sentence "Guten Tag, .... " (synthesis by minimal rules, no prosody): gtag.wav
- Example for Reduction in German Sentence "mit dem Boot" to "mim Boot" (see Kröger 1993 Journal Phonetica): boot.wav
- Intonation contours (synthetic fist, natural is following) (copy synthesis using two mass model): bababa2.wav
2 ) A 3D-articulatory-acoustic synthesizer including a gestural control concept has been developed for
high quality synthesis of speech and singing.
Currently the model is capable of synthesizing unrestricted text including all sound types (vowels, plosives,
fricatives, ...) and unrestricted songs for untrained male and female voices.
(Birkholz & Kröger 2007: Abstracts of PEVOC, Groningen, Poster).
Examples:
- a) Video and sound example for speech: Naechster Halt Hamburg
- b) Sound example for singing: Dona Nobis Pacem
References:
- Kröger BJ, Birkholz P, Kannampuzha J, Neuschaefer-Rube C (2010) Modeling different voice qualities for female and male talkers using a geometric-kinematic articulatory voice source model: preliminary results. In: S Fuchs, P Hoole, C Mooshammer, M Zygis (eds.) Between the regular and the particular speech and language. (Peter Lang, Frankfurt) pp. 97-124 (pdf)
- Kröger BJ, Birkholz P (2009) Articulatory Synthesis of Speech and Singing: State of the Art and Suggestions for Future Research. In: Esposito A, Hussain A, Marinaro M (eds) Multimodal Signals: Cognitive and Algorithmic Issues. LNAI 5398 (Springer, Berlin), pp. 306-319 (pdf)
- Kröger BJ, Birkholz P (2007) A gesture-based concept for speech movement control in articulatory speech synthesis. In: Esposito A, Faundez-Zanuy M, Keller E, Marinaro M (eds.) Verbal and Nonverbal Communication Behaviours, LNAI 4775 (Springer Verlag, Berlin, Heidelberg) pp. 174-189 (pdf, doi)
- Birkholz P, Jackel D, Kröger BJ (2007) Simulation of losses due to turbulence in the time-varying vocal system. IEEE Transactions on Audio, Speech, and Language Processing 15: 1218-1225 (pdf, doi)
- Birkholz P, Jackel D, Kröger BJ (2006) Construction and control of a three-dimensional vocal tract model. Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2006) (Toulouse, France) pp. 873-876 (pdf)
- Kröger BJ (1997) On the quantitative relationship between subglottal pressure, vocal cord tension, and glottal adduction in singing. Proceedings of the Institute of Acoustics 19 (5): 479-484 (ISMA97) (pdf)
- Kröger BJ (1996) Artikulatorische Sprachsynthese (Eingeladener Vortrag) In: Fortschritte der Akustik: Plenarvorträge und Fachbeiträge der 22. Deutschen Jahrestagung für Akustik, DAGA '96. (DEGA, Oldenburg) pp. 96-100 (pdf)
- Kröger BJ (1993) A gestural approach for controlling an articulatory speech synthesizer. Proceedings of Eurospeech 1993 (Berlin, Germany), pp. 1903-1906 (pdf)
- Kröger BJ (1992) Minimal rules for articulatory speech synthesis. In: J Vandewalle, R Boite, M Moonen, A Oosterlinck (Hrsg.) Signal Processing VI: Theories and Applications Amsterdam, Elsevier) pp. 331-334 (pdf)
- Kröger BJ (1991) Zur Auswirkung der Glottis-Sprechtrakt-Kopplung auf die Stimmreinheit. Sprache-Stimme-Gehör 15:139-142 (pdf)
- Kröger BJ (1989) Die Synthese der weiblichen Stimme unter besonderer Berücksichtigung der Phonation. Unveröffentlichte Dissertation. Universität zu Köln. (pdf)
Apraxia of Speech (AOS) and Childhood Apraxia of Speech (CAS)
see pdf of an introductory lecture: AOS: The poorly understood speech disorder
Papers on motor planning by using speech action units started in 2010 (see publications)
References:
- Becker-Redding U, Kirchner M, Kröger BJ (2015) Kindliche Sprechapraxie und KoArt: eine Evaluationsstudie zur Therapieeffektivität.
In: Abstractband 44. Jahreskongress des dbl (Düsseldorf) p. 23
(pdf)
- Schulz S, Heim S, Willmes K, Kröger BJ (2014) Analyse sprechapraktischer Fehler im System artikulatorischer Gesten.
Sprache Stimme Gehör 38: Se7f
(doi)
- Kröger BJ, Becker-Redding U (2013) Wann ist Therapieresistenz bei kindlichen Sprechstörungen ein Hinweis auf kindliche Sprechapraxie?
Proceedings of DGPP 2013 (Bochum, Germany) (pdf)
- Kröger BJ, Miller N, Lowit A, Neuschaefer-Rube C. (2011) Defective neural motor speech mappings as a source for apraxia of speech:
Evidence from a quantitative neural model of speech processing. In: Lowit A, Kent R (eds.)
Assessment of Motor Speech Disorders. (Plural Publishing, San Diego, CA) pp. 325-346
(pdf)
- Kröger BJ (2010) Computersimulation sprechapraktischer Symptome aufgrund funktioneller Defekte.
Sprache-Stimme-Gehör 34: 139-145
(pdf)
Treatment of speech disorders using SpeechTrainer
SpeechTrainer is a software-package for 2D-visualisation of speech movements (download SpeTra). SpeechTrainer can be used as a visual stimulation technique in treatment of different types of speech disorders.(see Funk_2006, Kröger_2005)
- Use of SpeTra in treatment of articulation disorders:
Albert_diploma_thesis_2005 - Use of SpeTra in treatment of apraxia of speech:
Gotto_diploma_thesis_2005
References:
- Kröger BJ (2009) Visuelle Animation der Artikulation als Therapiehilfe bei Spechstörungen:
Eine neurophonetische Begründung. Sprache-Stimme-Gehör 33: 179-185
(pdf)
- Funk J, Montanus S, Kröger BJ (2006) Therapie von neurogenen und kindlichen Sprechstörungen mit dem Programm SpeechTrainer. Forum Logopädie 20 (2): 6-13 (pdf)
- Kröger BJ, Gotto J, Albert S, Neuschaefer-Rube C (2005) A visual articulatory model and ist application to therapy of speech disorders: a pilot study. In: S Fuchs, P Perrier, B Pompino-Marschall (Hrsg.) Speech production and perception: Experimental analyses and models. ZASPiL 40: 79-94. (pdf)
Acoustic and perceptual methods in diagnosis of speech disorders
Phonetically oriented methods in diagnosis of speech disorders are mainly perceptually based. The main
drawback of these methods is its subjectivity. Thus acoustically based methods could be advantageous.
But the main problem of acoustically based methods in diagnosis of
speech disorders is to extract meaningful or significant acoustic parameters.
Different phonetically oriented measures were tested for improving or refining the diagnosis of speech disorders:
-
Childhood apraxia of speech:
- Ziethe_SSG_2013
- Franz_ICSMC_2006
- Dysarthria:
- Kröger_DAGA_2005
- Kröger_DAGA_2003
- Siegert_diploma_thesis_2004
- Auditory Processing Disorders:
References:
- Kukla H, Kleiser N, Kröger BJ (2014) Episodische Dysarthrie bei Hirnstammkompression: akustisch-phonetische und auditiv-perzeptuelle Analyse. In: Hoffmann R (ed.) Studientexte zur Sprachkommunikation: Elektronische Sprachsignalverarbeitung 2014 (TUDpress, Dresden, Germany), pp. 169-176
- Jäckel R, Strecha G, Hoffmann R, Kröger BJ (2014) Untersuchung segmentaler und suprasegmentaler Charakteristiken des Sprechsignals bei Morbus Parkinson. In: Hoffmann R (ed.) Studientexte zur Sprachkommunikation: Elektronische Sprachsignalverarbeitung 2014 (TUDpress, Dresden, Germany), pp. 161-168
- Ziethe A, Springer L, Willmes K, Kröger BJ (2013) Untersuchung zur Kernsymptomatik bei Kindern mit einer kindlichen Sprechapraxie
im Alter von 4-7 Jahren. Sprache - Stimme - Gehör, in press
(doi)
- Mühlhaus J, Vorwerk W, Kröger BJ (2007) Zur Diagnostik der Auditiven Verarbeitungs- und Wahrnehmungsstörungen (AVWS): zwei Verfahren zur Identifikation und Diskrimination ambivalenter akustischer Stimuli im Vergleich. Die Sprachheilarbeit 5: 205-212(pdf)
- Franz, E, Willmes K, Neuschaefer-Rube C, Kröger BJ (2006) Acoustical and perceptive analyses of vowels in suspected developmental apraxia of speech: a pilot study. Abstracts of 5th International Conference of Speech Motor Control (Nijmegen, Netherlands). Also: Stem-, Spraak- en Taalpathologie 14, Suppl. p. 89. (pdf)
- Kröger BJ, Siegert M, Neuschaefer-Rube C (2005) Phonatorisch-artikulatorische Kompensation bei einem ALS-Patienten mit schwerer dysarthrischer Sprechstörung. In: Fortschritte der Akustik: 31. Deutsche Jahrestagung für Akustik, DAGA '05. DEGA, Berlin, pp. 75-76. (pdf)
- Kröger BJ, Diem A, Siegert M (2003) Artikulatorische und akustische Methoden in der Diagnostik und Therapie von Sprechstörungen. In: Fortschritte der Akustik: 29. Deutsche Jahrestagung für Akustik, DAGA '03. DEGA, Oldenburg, pp. 754-755. (pdf)